

What would come to mind if you were asked, “why do we need a Version Control System (VCS)?”
Granted, it’s not your typical question these days. Version Control is a staple of software development tooling, and there are many types of versioning systems, not just those for source code. In contrast, versioning was not necessarily part of a developer’s toolkit twenty years ago. In this second blog post on Git and VCS, I want to relate the jump from basic to a more advanced use of Version Control. It is not a deep topic, but if you want to make history while managing your source files, this theme has been helpful to others that I’ve worked with. I hope it is for you, too.
Due to its majority place in the industry and software development, DevOps and Infrastructure-as-Code, Git is referenced and elaborated on in this blog.
The Background on Why Version Control Is Necessary
 As a developer for apps or infrastructure, whenever you commit code or check in a file, you’re building an archive. The narrative used to be, that when faced with the problem to scale code management and platform, it was hard to influence developers to keep revisions of their source code. In presenting the use case to these folks, I would answer the question of why we need Version Control. Fifteen or twenty years ago, it did not relate to pipelines, that is a contemporary reason – and positive change forward.
As a developer for apps or infrastructure, whenever you commit code or check in a file, you’re building an archive. The narrative used to be, that when faced with the problem to scale code management and platform, it was hard to influence developers to keep revisions of their source code. In presenting the use case to these folks, I would answer the question of why we need Version Control. Fifteen or twenty years ago, it did not relate to pipelines, that is a contemporary reason – and positive change forward.
Fortunately, business drivers surfaced that comprised a need for DevOps and Configuration Management and reached consensus. Big words describing disruptors like “idempotent” and “immutable” began to enter the vernacular. These disruptors have existed in the annals of computer science, but the supporting data was not published by our software industrial engineers. The publishing of these trends are industry relevant entities like Gartner, Forrester, State of DevOps yearly survey and report, The Phoenix Project, the Continuous Delivery book, etc.
Making History in Your VCS – Technically Speaking
This post will now get into technical Git, to illustrate ways to manage and monitor history.
A set of commands are fundamental to Git. Resources abound to learn them, and I’ve listed just a few at the end of this blog under Additional Resources.
Here are some of those commands:
- commit (and understanding the commit hash)
- log
- clone, pull, merge, rebase
- diff
- status
Take a building block approach to your use of Git. The most basic process that we can take for granted is the check-out and check-in process. Right away Git simplifies this. Once you have a repo, there’s effectively no check-out. Its workflow is all about managing your repo locally and remaining in sync with the rest of your team. You might think of it as client and server, and for the most part that’s accurate. Every repo is a distributed copy of the other. The skill in knowing your Git is to keep it simple and friendly from a commit perspective with your team. That is where keeping the history in mind is beneficial.
Taking (G)it Step by Step
To illustrate some of the more advanced concepts in simple terms, I cloned a common example GitHub project called, spring-music.
Let’s go, start committing code, do that first check in. You can look at your history right from the start. Do you have a commit hash? Create a branch, and guess what? Same revision and same commit hash. Commit a new change, atomically speaking, of course.
Once you are in the groove of coding your own and collaborating with other team members, you will find it helpful to contribute to good history maintenance.
Merge has the following approaches:
- Source code level integration.
- Resolve conflicts, if any, as you never know when to expect them. Think of it as driving on a quiet road, cruising along and as you approach a green light, it mindlessly changes to yellow and red, seemingly taking minutes off your life.
- Choose type of merge –
- pull request (GitHub merge request functionality)
- Local repo and then push up
- And believe it or not – > Git pull
- Unless you supply the –rebase parameter
- Git pull is a cleverly cloaked fetch and merge operation
4 Core Scenarios
The following branches have been staged with changes to simplify the flow. The essence of these simplistic commits may surprise you and bring home the effectiveness of knowing a next level, or reviewing a next level, of Git commands. Now let’s take a look at our branches setup ahead of this exercise to provide the basic scenarios for the following commands:
- merge
- rebase
- merge with squash option
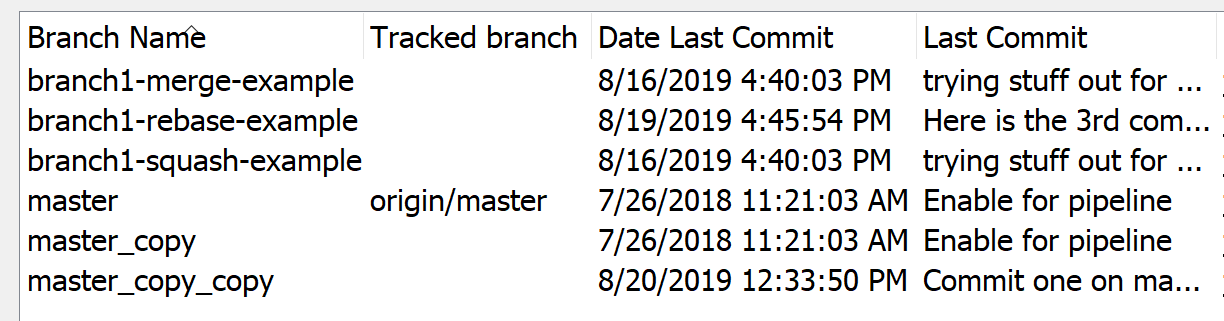
I will walk through 4 scenarios, all intended to give a glimpse into Git history. Frankly I avoided most of these options like rebase and squash early on. Then I recognized that teams looking to scale do care and are receptive to learn these.

Expected outcome:
Your version graph will look as if you committed directly on master, and if the feature branch is deleted, no visible evidence shows that you branched.

Here in Scenario 1, notice that 4 files change, while the commit history appears as if the changes were made directly on this branch.

In Scenario 2 below, the version graph will depict the branching more clearly because the merge operation is not able to fast-forward the commits directly inline.

Expected outcome:
Feature branch merged back to master, at least one change made directly on master, and the feature branch is being merged back to master.
What order will your history be in?
The history lays the feature branch on top of master, chronologically out of order but it doesn’t affect the code function. If there was a conflict based on the same file changing, then the merge conflict would be resolved by the developer to successfully complete the merge. We see the branch through the versioning graph from the Git log command.
We start with master_copy as follows:

We’ll next merge our merge branch, exactly alike to the rebase branch, but we will not concern ourselves with the history order. In other words, merging will lay the new commits from the feature branch as latest commits, thought they are not in a time series order. Once again, you have the same 4 files.
The branch is captured in the version graph:

This visibly presents the branching event; no difference exists in the code. By running a Git diff command for the master copy against both the merge and rebase example feature branches, it yields the same result, that is the single commit that pre-existed on master copy.

Expected outcome:
Feature branch merged back to master, at least one change made directly on master, and the feature branch is being merged back to master.
What order will your history be in?
The rebase action orders your commit history chronologically.
Here is the master branch:

Here is the feature branch, to demonstrate the reordering of history – but this has no impact on the code functionality. Notice the discreet behavior, in how Git rewinds and replays. The log command now reveals the order:


Expected outcome:
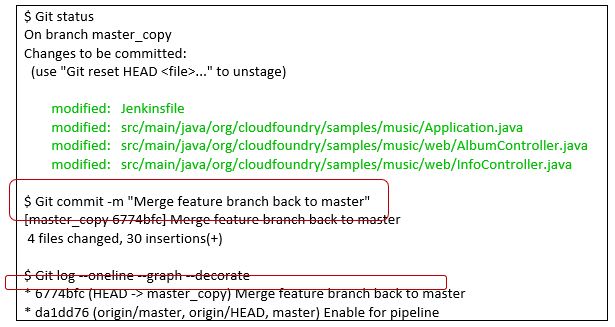
Feature branch merged back to master, depict using straight merge using the squash option. The history from the feature branch is lost but the advantage is the feature work is condensed into a single commit, must easier to read back on master. Remember, once you delete the feature branch, there will no longer be history that multiple commits took place on the feature branch, but do you always care once you’ve tested and released the software?
Check out the squash option of the merge command.

Now’s a good time to run the status command, just as if you were editing files, the squash parameter has instructed Git to stage the files for commit. Therefore, a commit will provide the atomic result and allow you to specify a meaningful comment in the act. 4 files become a single commit.
Pipeline Context
The code from application to CI/CD and Test-Driven Development, is a tapestry of code. With this complexity, what is the purpose of keeping close tabs on your commit, branch, tags and all history related therein?
To talk about practices, at this point everything is best, here are the essential justifications to use a VCS.
- Repeatability
- Backup (save yourself)
- Restore a previous check in
- Collaboration
The point about backup or save yourself from disaster if your C: drive crashes, usually provided the strongest case. This in turn held an audience’s attention. However, my favorite has always been the storied aspect. Without the ability to revert to a previous change, to manage your codeline and history, how would you be able to collaborate or perform better code reviews? Developers have incorporated these best practices and resistance has yielded over time.
Concluding Thoughts
We typically look at emerging or transformational technology opportunities through an optimist’s lens. I’ve done this throughout my career, the next big thing I would be so into, so dedicated and interested in, that it would reap benefits for my organization and my career. It took me several iterations, say in 5 to 8-year cycles, to realize that this isn’t a given. Being open and ready to tackle the better solutions for solving IT business problems builds skills and knowledge to apply solutions. To be successful, one needs to present the problem in a fresh and influential way.
As for Git: “As with many great things in life, Git began with a bit of creative destruction and fiery controversy.”
The refreshing news about Git, is it now has staying power, and it’s good for your career and to build quality infrastructure and applications. If you haven’t thought about how to polish your Git skills, the author hopes you upskill in this area.
Take this classic tale to heart. When you build your software, is your mindset that of stacking bricks or building a wall, one [brick] at a time all day long as you commit code? Or are you applying the code and configuration to a software solution that profits your company one commit at a time to achieve a vision towards a strategic roadmap? Building a better architecture? I’d love to hear your point of view regarding these questions in the comment section below.
As with the greater endeavors and points in time of tremendous human invention, Git fits the bill of transformation. It is this piece of evolution, finding a majority acceptance of how people store and collaborate that sparks innovation and enables the standardization for a multi-faceted idea like DevOps to evolve. You are witness to repeatable processes, desired state configuration and intelligent pipelines. We are in business to eschew science fiction through immutable behaviors and idempotency one atomic commit at a time. Dear Reader, these are indeed exciting times!
Sources
There are many references to the bricklayers’ story, here’s a concise post that embraces the analogy and captures my imagination in the way it relates to DevOps.
Additional Resources
- Git Merge vs. Rebase: What’s the Diff? – Hacker Noon
- Version Control – When Do You Use Git Rebase Instead of Git Merge? – Stack Overflow
- Learn GitFlow Branching Approach
- Pro Git Book
Read Part I of this 2-Part Series
Best Practices for Scaling Version Control in the Large Enterprise
